
wireless_status kernel sysfs API
The new usb_set_wireless_status() driver API function can be used by drivers of USB devices to export whether the wireless device associated with that USB dongle is turned on or not.
To quote the commit message:
This will be used by user-space OS components to determine whether the battery-powered part of the device is wirelessly connected or not, allowing, for example: - upower to hide the battery for devices where the device is turned off but the receiver plugged in, rather than showing 0%, or other values that could be confusing to users - Pipewire to hide a headset from the list of possible inputs or outputs or route audio appropriately if the headset is suddenly turned off, or turned on - libinput to determine whether a keyboard or mouse is present when its receiver is plugged in.
This is not an attribute that is meant to replace protocol specific APIs [...] but solely for wireless devices with an ad-hoc “lose it and your device is e-waste” receiver dongle.
Currently, the only 2 drivers to use this are the ones for the Logitech G935 headset, and the Steelseries Arctis 1 headset. Adding support for other Logitech headsets would be possible if they export battery information (the protocols are usually well documented), support for more Steelseries headsets should be feasible if the protocol has already been reverse-engineered.
As far as consumers for this sysfs attribute, I filed a bug against Pipewire (link) to use it to not consider the receiver dongle as good as unplugged if the headset is turned off, which would avoid audio being sent to headsets that won't hear it.
UPower supports this feature since version 1.90.1 (although it had a bug that makes 1.90.2 the first viable release to include it), and batteries will appear and disappear when the device is turned on/off.

A turned-on headset
Se former à l’informatique sans quitter son canapé : Utopie ou réalité ?
Le boom des formations en ligne : Avantages et inconvénients
Depuis quelques années, nous avons vu fleurir une multitude de formations en ligne dédiées à l’apprentissage de l’informatique. Des sites comme Udemy, Coursera, et OpenClassrooms offrent des cours de qualité, souvent accessibles à moindre coût, voire gratuits. Le grand avantage réside dans la flexibilité : on peut apprendre à son propre rythme, depuis son canapé, sans contrainte géographique.
Toutefois, cette flexibilité s’accompagne de quelques inconvénients notables. La motivation est un facteur clé pour réussir ce type de formation. Sans la rigueur et le cadre d’une classe traditionnelle, il est facile de procrastiner. De plus, l’absence d’interaction humaine peut être un frein pour ceux qui ont besoin d’un contact direct avec un enseignant pour bien assimiler les concepts.
Stratégies pour maximiser son apprentissage à domicile
Pour tirer le meilleur parti de ces formations en ligne, nous recommandons d’adopter quelques stratégies simples mais efficaces :
- Établir un planning : Fixez des créneaux horaires dédiés à l’apprentissage, comme si vous alliez à des cours en présentiel.
- Créer un espace de travail dédié : Évitez de travailler depuis votre lit ou le canapé ; un bureau dédié favorisera la concentration.
- Utiliser des outils de suivi de progression : Des applications comme Trello ou des tableaux Excel peuvent aider à suivre votre avancement et rester motivé.
- Rejoindre des forums ou des groupes d’étude en ligne : Les communautés comme Reddit, Stack Overflow ou des groupes Facebook peuvent fournir du soutien et des réponses à vos questions.
Success stories : Ceux qui ont réussi grâce aux formations à distance
Il ne manque pas d’exemples de personnes ayant réussi à transformer leur vie professionnelle grâce aux formations en ligne. Prenons le cas de Maxime, un ancien chauffeur de taxi de 45 ans qui a appris à coder grâce à OpenClassrooms. Aujourd’hui, il travaille en tant que développeur web pour une start-up innovante. Ou encore Camille, une mère au foyer qui, après avoir suivi des cours sur Coursera, a décroché un poste de data analyst dans une grande entreprise technologique.
Selon une étude de LinkedIn Learning, 69% des professionnels considèrent que les formations en ligne ont autant de valeur que les formations traditionnelles. Il est clair que ces programmes peuvent offrir des opportunités réelles, à condition d’y mettre de la volonté et de la discipline.
En résumé, se former à l’informatique depuis chez soi n’est plus une utopie, mais une réalité accessible à tous. Les formations en ligne offrent une alternative flexible et souvent moins coûteuse aux méthodes traditionnelles, à condition de rester rigoureux et motivé.
The post <h1>Se former à l’informatique sans quitter son canapé : Utopie ou réalité ?</h1> appeared first on gnomelibre.fr.
Apprendre à coder en une semaine : mythe ou réalité ?
Les méthodes intensives : quelles sont-elles et sont-elles efficaces ?
Quand on parle apprentissage intensif du codage, plusieurs techniques se démarquent. Les bootcamps de programmation sont parmi les plus connus. Ces formations, souvent d’une durée de quelques semaines, immergent totalement les participants dans l’univers du développement web. Leurs avantages ? Efficacité, immersion totale et enseignement pratique.
Toutefois, est-ce que ces méthodes sont vraiment efficaces ? Nous pensons que cela dépend de plusieurs facteurs, notamment de votre motivation, votre expérience préalable et la qualité du bootcamp choisi. En théorie, il est possible d’acquérir une compréhension de base du codage en une semaine, surtout si on se concentre sur un langage précis comme le HTML ou le Python. Cependant, atteindre un niveau professionnel en si peu de temps reste un défi de taille.
Témoignages : ceux qui ont tenté et réussi à coder en une semaine
Plusieurs personnes ont tenté l’expérience de l’apprentissage intensif. Prenons l’exemple de Jean Dupont, un graphiste de 32 ans, qui a suivi une formation de 70 heures en cinq jours pour apprendre à développer des sites web. Jean affirme qu’il a pu créer des pages web simples avec HTML et CSS à la fin de la semaine, mais il admet que maîtriser des concepts plus complexes de JavaScript a nécessité plusieurs semaines supplémentaires de pratique.
D’autres témoignages abondent dans le même sens. Marie Leroy, une ingénieure reconvertie, raconte comment elle a appris les bases de Python en une semaine grâce à un module intensif en ligne, mais souligne qu’elle a dû continuer à pratiquer quotidiennement pendant des mois pour vraiment se sentir à l’aise.
Les limites et les pièges de la promesse d’une semaine : analyse critique
Il est crucial de comprendre que promettre une maîtrise du codage en une semaine peut être trompeur. Les formations intensives peuvent fournir une bonne base de départ, mais elles ne remplacent pas l’expérience et la pratique continue.
- Fatigue mentale : Les programmes intensifs peuvent être épuisants, et l’information peut être difficile à retenir sans un temps de repos adéquat.
- Absence de maturité technique : Acquérir des connaissances théoriques est une chose, mais les appliquer efficacement et résoudre des problèmes pratiques demande du temps.
- Surcharge d’information : En une semaine, les concepts sont souvent survolés, ce qui peut mener à une compréhension superficielle plutôt que profonde.
À notre avis, fixer des objectifs réalistes est essentiel. Nous recommandons de commencer par des petits projets concrets et de pratiquer régulièrement pour renforcer ses compétences. Utiliser des ressources comme Codecademy, FreeCodeCamp ou des vidéos YouTube peut aider à combler des lacunes.
En somme, il est possible d’apprendre les bases du codage en une semaine, mais devenir un programmeur compétent nécessite bien plus de temps et de pratique. Le véritable défi est de continuer à apprendre et à s’adapter dans ce domaine en constante évolution.
The post <h1>Apprendre à coder en une semaine : mythe ou réalité ?</h1> appeared first on gnomelibre.fr.

systemd (and dracut) in next openSUSE
For those of you who didn't attend the conference, you can watch my talk on YouTube (thanks to openSUSE awesome video team for the recording):
And you can even get my slides ;)

Occupation de l’antenne et API Prometheus
À côté de munin il y a aussi à la radio collectd et graphite, ça fait des années mais l’utilisation n’a jamais vraiment décollé, c’est juste utilisé pour remplir une page avec trois graphes, niveau sonore, nombre d’auditeurs sur le stream, et état du switch studio.
Dans mes archives je trouve une première mention de l’utilisation à la radio fin 2012, c’est dans un fil de discussion qui parle d’ailleurs également de munin, je ne sais plus trop ce qui avait pu me pousser à expérimenter autre chose mais ça semblait à la mode il y a dix ans; je retrouve par exemple un article "An Introduction to Tracking Statistics with Graphite, StatsD, and CollectD", 23 mai 2014. C’est aussi la période d’écriture du site web de la radio (2013) et je me souviens avoir utilisé django-statsd pour visualiser les temps de rendu des différentes vues.
Dans ces années-là, circa 2014, j’avais produit une page récapitulative de la présence à l’antenne (vs la diffusion automatique, d’émissions préenregistrées ou de musiques), ça utilisait l’API de Graphite pour obtenir les données qui arrivaient formatées ainsi :
[
{
"tags": {
"name": "collectd_noc_panik.curl_json-switch.gauge-nonstop-on-air",
"summarize": "1h",
"summarizeFunction": "sum"
},
"target": "summarize(collectd_noc_panik.curl_json-switch.gauge-nonstop-on-air, \"1h\", \"sum\")",
"datapoints": [
[0.0, 1703890800], [0.0, 1703894400], [0.0, 1703898000], ...
]
}
]
c’est-à-dire une série de 0 quand le studio est à l’antenne et 1 quand c’est la diffusion automatique, associés à des timestamps. Tout ça était assemblé pour remplir un tableau de semaines,

Ça a tourné trois ans puis ça a été oublié mais hier j’ai eu envie d’actualiser ça et j’ai retrouvé une version du code a priori jamais utilisée, qui était encore en Python 2 mais améliorait la présentation pour utiliser la palette de couleurs Viridis (que je venais sans doute de découvrir via cette présentation à la SciPy).
Après une première mise à jour du code pour fonctionner avec Python 3, je me suis dit que ça pouvait être une bonne idée de regarder si ça pouvait être fait via les données stockées dans Prometheus, pour pouvoir supprimer collectd et graphite (pour lesquels, contrairement à munin, j’ai peu d’attachement).
J’ai vite abandonné l’idée de faire faire par Prometheus les regroupements par heure, j’ai plutôt récupéré les échantillons pris toutes les cinq minutes, mais ça faisait trop pour l’API (qui annonce un max de 11000 valeurs possibles dans la réponse, alors qu’il en aurait fallu le quadruple pour couvrir une année), j’ai donc dû multiplier les appels, et par simplicité j’ai juste groupé par semaines,
start = datetime.datetime(year, 1, 1, 0, 0, tzinfo=ZoneInfo('Europe/Brussels'))
start = start - datetime.timedelta(days=start.weekday())
for i in range(53):
end = start + datetime.timedelta(days=7)
# TODO: switch to %:z once available (python 3.12)
start_time = start.strftime('%Y-%m-%dT%H:%M:%S%z').removesuffix('00') + ':00'
end_time = end.strftime('%Y-%m-%dT%H:%M:%S%z').removesuffix('00') + ':00'
resp = requests.get(
'.../prometheus/api/v1/query_range', params={
'query': 'panik_switch_status{info="nonstop-on-air"}',
'start': start_time,
'end': end_time,
'step': '5m'})
L’API de Prometheus attend une heure précisant le fuseau horaire (conforme à la RFC 3339), sous la forme +01:00 mais le formatage des dates dans Python proposait uniquement %z, qui donne +0100, il faut attendre Python 3.12 pour avoir %:z qui fournira +01:00. Ça arrivera avec la prochaine mise à jour Debian mais en attendant, code bricolé moche.
Pas de surprise, les données obtenues ressemblent à ce qu’il y avait via Graphite, les timestamps et les valeurs,
{
"data": {
"result": [
{
"metric": {
"name": "panik_switch_status",
"info": "nonstop-on-air",
"instance": "noc:9100",
"job": "node"
},
"values": [
[1704063600, "0"], [1704063900, "0"], [1704064200, "0"], ...
]
}
],
"resultType": "matrix"
},
"status": "success"
}
et tadam le résultat,

où on voit l’émission de la soirée/nuit du dimanche, la matinale du lundi et du mardi, une panne le mardi 20 février, etc.
Prometheus & Grafana pour le suivi à la radio
Il y a quelques années déjà j’écrivais à propos de munin, fidèle outil lowtech, c’est toujours vrai mais récemment je l’ai plutôt délaissé au profit de Prometheus et, pour la peine absolument pas lowtech, Grafana.
Dans les motivations pour ce changement il y a surtout la mise en place d’un système d’alertes, par exemple quand le niveau audio de la radio devient trop faible ou que l’enregistrement automatique tombe en panne (il y a longtemps on utilisait nagios mais ça fait des années que c’est à l’arrêt et qu'on n'avait plus rien). Pour ça Prometheus suffirait mais tant qu’à collecter les données, autant en faciliter l’exploration.
Pour Prometheus il y a le nécessaire dans Debian, pour Grafana pas mais le projet met à disposition un dépôt (apt.grafana.com), ça s’installe sans problème mais ensuite ça a été plutôt pénible à configurer pour fonctionner derrière un reverse-proxy, dans un préfixe. Pas de réussite via la documentation, c’est finalement un article de Jack Henschel (Configure Prometheus on a Sub-Path behind Reverse Proxy) qui m’a aidé. Adapté à Debian il s’agit de modifier /etc/default/prometheus pour ajouter --web.external-url=/prometheus/ --web.route-prefix=/prometheus/ dans la variable ARGS. Pour les alertes il faut également préciser l’affaire,
# Alertmanager configuration alerting: alertmanagers: - scheme: http - path_prefix: "prometheus/" static_configs: - targets: ['localhost:9093']
Avec ça et la collecte des données utiles le système d’alertes est opérationnel, par exemple une alerte pour le niveau audio est définie ainsi :
- alert: Volume
expr: panik_volume < -60
for: 10m
labels:
severity: critical
annotations:
title: niveau sonore
summary: volume très bas, sans doute du silence
Pour Grafana pour le fonctionnement dans un préfixe derrière un reverse-proxy c’était plus simple à trouver, dans /etc/grafana/grafana.ini, variable root_url. À explorer le fichier de configuration de Grafana, j’ai noté aussi que l’authentification pouvait être déléguée à un serveur OpenID Connect, c’est pratique pour directement donner l’accès à tous les membres de la radio,
[auth.generic_oauth] enabled = true name = PanikDB allow_sign_up = true auto_login = false client_id = grafana client_secret = ... scopes = openid email profile email_attribute_name = email auth_url = https://panikdb.radiopanik.org/oauth/authorize token_url = https://panikdb.radiopanik.org/oauth/token api_url = https://panikdb.radiopanik.org/oauth/user-info
À ce sujet il y a possibilité de désactiver la connexion interne (disable_login = true) mais curieusement l’écran de connexion continue à présenter des champs Username/Password.
Dans la configuration un dernier élément utile est la mise en place d’un tableau de bord personnalisé sur la page d’accueil, variable default_home_dashboard_path. (c’est dommage que ça ne puisse pas être fait via l’interface, ça oblige à maintenir un export JSON de la configuration du tableau de bord sur le disque).
Quand j’avais écrit sur munin c’était à propos de graphe de suivi pour notre émetteur, j’ai refait les mêmes,
#! /usr/bin/python3
import requests
from prometheus_client import CollectorRegistry, Gauge
from prometheus_client.exposition import generate_latest
session = requests.Session()
session.get('http://emetteur.panik/api/auth', data={'password': 'XXX'}, timeout=5)
r = session.get('http://emetteur.panik/api/getParameters.js', timeout=5)
session.get('http://emetteur/api/logout', timeout=5)
registry = CollectorRegistry()
for key in (
'transmitter.power',
'transmitter.set_power',
'meters.fwd_power',
'meters.rev_power',
'meters.pa_voltage',
'meters.aux_voltage',
'meters.pa_temp',
'meters.peak_deviation',
):
gauge = Gauge('emetteur_%s' % key.replace('.', '_'), key.replace('.', '_'), registry=registry)
gauge.set(float(r.json()[key]))
print(generate_latest(registry).decode())
et voilà donc un graphe affichant emetteur_meters_pa_temp : (passionnant)

Pour le moment parce que ça ne coûte pas grand chose je garde munin en place.
3D Printing Slicers
I recently replaced my Flashforge Adventurer 3 printer that I had been using for a few years as my first printer with a BambuLab X1 Carbon, wanting a printer that was not a “project” so I could focus on modelling and printing. It's an investment, but my partner convinced me that I was using the printer often enough to warrant it, and told me to look out for Black Friday sales, which I did.
The hardware-specific slicer, Bambu Studio, was available for Linux, but only as an AppImage, with many people reporting crashes on startup, non-working video live view, and other problems that the hardware maker tried to work-around by shipping separate AppImage variants for Ubuntu and Fedora.
After close to 150 patches to the upstream software (which, in hindsight, I could probably have avoided by compiling the C++ code with LLVM), I manage to “flatpak” the application and make it available on Flathub. It's reached 3k installs in about a month, which is quite a bit for a niche piece of software.
Note that if you click the “Donate” button on the Flathub page, it will take you a page where you can feed my transformed fossil fuel addiction buy filament for repairs and printing perfectly fitting everyday items, rather than bulk importing them from the other side of the planet.
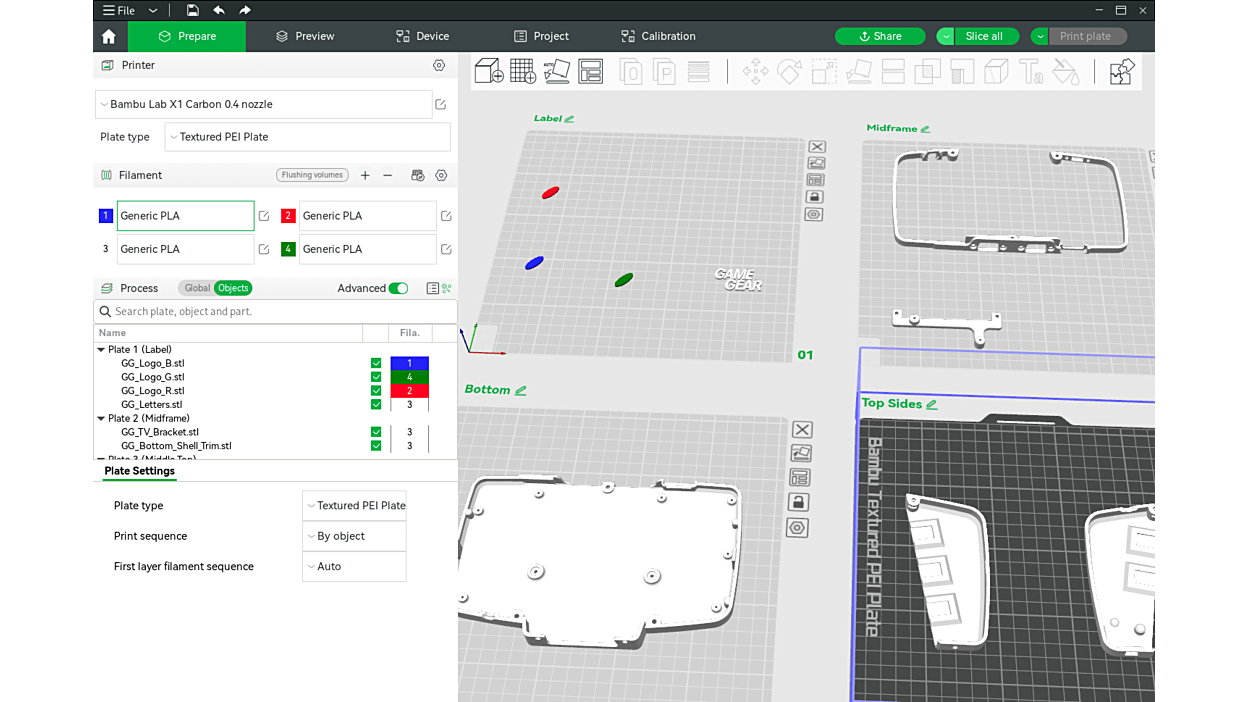
Preparing a Game Gear consoliser shell
I will continue to maintain the FlashPrint slicer for FlashForge printers, installed by nearly 15k users, although I enabled automated updates now, and will not be updating the release notes, which required manual intervention.
FlashForge have unfortunately never answered my queries about making this distribution of their software official (and fixing the crash when using a VPN...).
Rhythmbox
As I was updating the Rhythmbox Flatpak on Flathub, I realised that it just reached 250k installs, which puts the number of installations of those 3D printing slicers above into perspective.

The updated screenshot used on Flathub
Congratulations, and many thanks, to all the developers that keep on contributing to this very mature project, especially Jonathan Matthew who's been maintaining the app since 2008.

Warning: This blog post contains a lot of talk about feelings, loss, and discussion of a suicide.
Recently, I have been thinking a lot about loss. My nephew died just a few months ago, after a short life with Duchennes Muscular Dystrophy. A neighbour recently took her own life, leaving a husband and two children behind. And today I learned that someone I have known for 15 years in the open source world recently passed away through a mailing list post. In each case, I have struggled with how to grieve.
My nephew has been ill for a long time, and we have been open in my family about taking advantage of opportunities we have to spend time with him for the past few years, because we knew he would not live much longer. And yet, death is always a surprise, and when we got a phone call one Saturday in November to let us know that he had passed away in his sleep, my first instincts were logistical. “I have a work trip coming up – when will the funeral service happen? Can I travel to Asia and get home in time, or do I need to cancel my trip? What is the cheapest way to get home? Who should travel with me?” When I got home, the funeral is a multi-day collective grieving, with neighbours, cousins, uncles and aunts arriving to pay their respects, express their condolences, spend time with the family. It was not until we were shovelling dirt on top of the casket that I really thought about the finality of the burial – I will never see my nephew again.
And yet, I was not overwhelmed with grief. I have never really known him intimately. How well do you know a child 25 years your younger, after you leave home and live abroad? How close of a connection do any thirty-somethings have with their teenage nieces and nephews? I second-guessed my emotions. Should I feel sadder? Is there an appropriate way to grieve? In the end, I decided to allow myself to feel the feelings I felt, and not to try to figure out whether I “should” be feeling differently. But avoiding self-judgement was difficult.
Last week, when we got the news about our neighbour, it hit me pretty hard. We knew the family well, had been to barbecues and play-off games in their house. I had coached basketball with her husband, one of their sons was in the team. Initially, we read that she had “passed away suddenly”, it was only through school bus stop gossip that we learned that she had committed suicide. We learned that she had been suffering from depression, that her life had not been easy for the past few months. I felt a great sadness, and also a little guilt. We had enjoyed her company in the past, but I knew nothing of her life. I was about to leave on a work trip, I would miss her memorial service and funeral. I was told that the ceremonies were very emotional, and really felt like the community coming together. The priest leading the service spoke openly about suicide and depression, and my wife said that his ceremony gave her a great sense of peace, removing the veil from some of the awkwardness that she felt around the topic. It gave the community an opportunity to start healing.
But I was not there. Now, I have all of these other thoughts about the appropriate way for me to grieve again. My instinct is to call to their house to express my condolences, but I am afraid to. This time, I find myself comparing my feelings to those of her family. I imagine how they must be feeling. Surely they are devastated, probably angry, maybe even feeling guilty. I think about her sons, the same age as two of my own sons, and I wonder what their lives will be like now. What right do I have to feel grief, or to impose on their grieving to express my feelings to them? How would I react, in the same circumstances, if this acquaintance called to the house a week after a funeral ceremony? And then, I also feel guilt. Sure, we didn’t know each other that well, but could I have been there for her in some way? Was there some way that we could have helped? I think about how alone she must have felt.
And now, today, I have learned of the death of someone I would have called a friend. Someone I would regularly meet at conferences, who I got along very well with professionally and personally, two or three times a year. I was not a part of his life, nor he a part of mine. I’ve found myself tearing up this morning thinking about our interactions, realizing that we will never meet again. And once more, I struggle to find the appropriate way to grieve.
I don’t know why I felt compelled to write this – I have debated saving it as a draft, deleting it, writing it in a private text file. But I am sharing it. I think I feel like I missed a part of my education in dealing with loss. I feel like many people missed that part of our education. Maybe by sharing, other people can share their feelings in comments and help me further my own education. Maybe by reading, others who struggle with dealing with loss will realise they’re not alone. Maybe it will achieve nothing more than helping me deal with my own feelings by verbalizing them. Let’s find out…
Ubuntu 18.04.3 LTS is out, including GNOME stable updates and Livepatch desktop integration
Ubuntu 18.04.3 LTS has just been released. As usual with LTS point releases, the main changes are a refreshed hardware enablement stack (newer versions of the kernel, xorg & drivers) and a number of bug and security fixes.
For the Desktop, newer stable versions of GNOME components have been included as well as a new feature: Livepatch desktop integration.
For those who aren’t familiar, Livepatch is a service which applies critical kernel patches without rebooting. The service is available as part of an Ubuntu Advantage subscriptions but also made available for free to Ubuntu users (up to 3 machines). Fixes are downloaded and applied to your machine automatically to help reduce downtime and keep your Ubuntu LTS systems secure and compliant. Livepatch is available for your servers and your desktops.
Andrea Azzarone worked on desktop integration for the service and his work finally landed in the 18.04 LTS.
To enabling Livepatch you just need an Ubuntu One account. The set up is part of the first login or can be done later from the corresponding software-properties tab.
Here is a simple walkthrough showing the steps and the result:
The wizard displayed during the first login includes a Livepatch step will help you get signed in to Ubuntu One and enable Livepatch:
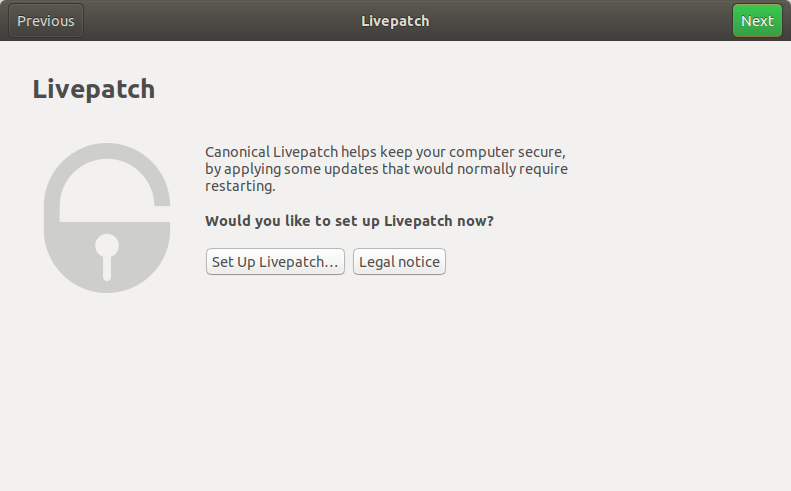

Clicking the ‘Set Up’ button invites you to enter you Ubuntu One information (or to create an account) and that’s all that is needed.
The new desktop integration includes an indicator showing the current status and notifications telling when fixes have been applied.
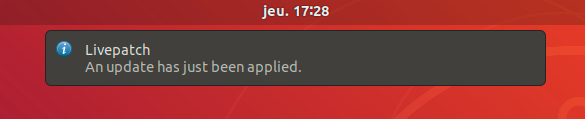
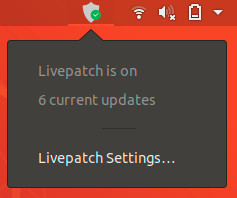
You can also get more details on the corresponding CVEs from the Livepatch configuration UI
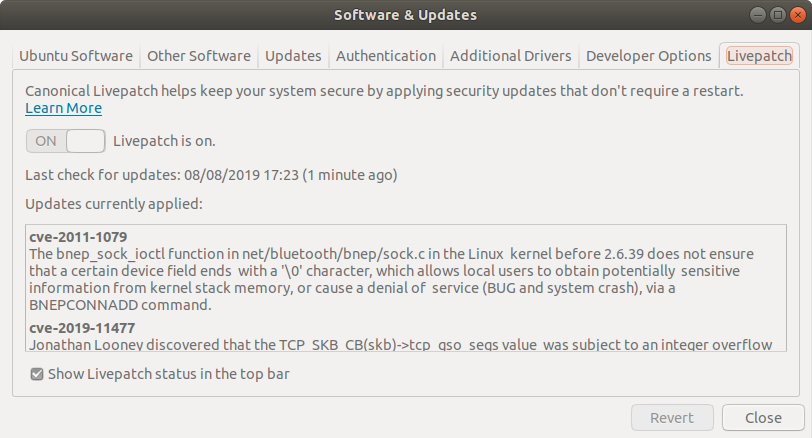
You can always hide the indicator using the toggle if you prefer to keep your top panel clean and simple.
Enjoy the increased security in between reboots!
Christian recently released bolt 0.8, which includes IOMMU support. The Ubuntu security team seemed eager to see that new feature available so I took some time this week to do the update.
Since the new version also featured a new bolt-mock utility and installed tests availability. I used the opportunity that I was updating the package to add an autopkgtest based on the new bolt-tests binary, hopefully that will help us making sure our tb3 supports stays solid in the futur 
The update is available in Debian Experimental and Ubuntu Eoan, enjoy!
The Great Gatsby and onboarding new contributors
I am re-reading “The Great Gatsby” – my high-school son is studying it in English, and I would like to be able to discuss it with him with the book fresh in my mind – and noticed this passage in the first chapter which really resonated with me.
…I went out to the country alone. I had a dog — at least I had him for a few days until he ran away — and an old Dodge and a Finnish woman, who made my bed and cooked breakfast and muttered Finnish wisdom to herself over the electric stove.
It was lonely for a day or so until one morning some man, more recently arrived than I, stopped me on the road.
“How do you get to West Egg village?” he asked helplessly.
I told him. And as I walked on I was lonely no longer. I was a guide, a pathfinder, an original settler. He had casually conferred on me the freedom of the neighborhood.
In particular, I think this is exactly how people feel the first time they can answer a question in an open source community for the first time. A switch is flipped, a Rubicon is crossed. They are no longer new, and now they are in a space which belongs, at least in part, to them.
Synology PhotoStation password vulnerability
Using a simple shell loop to run "ps ax | grep synophoto_dsm_user", it was possible to get user and password credentials for user on the NAS who had PhotoStation enabled with their DSM credentials.
Fortunately, by default, shell access on the NAS is not available (by ssh or telnet), it has to be enabled by the admin.
Still, it is a bad practise to pass credentials to process using command line, which can be intercepted.
PhotoStation version 6.7.1-3419 or earlier is vulnerable. I've contacted Synology and they should release a security fix really shortly, as well as a CVE for it.
Update (June 13, 2017): Synology has released a CVE and the vulnerability is fixed in PhotoStation 6.7.2-3429 or later. Remember to update this package on your NAS !

GStreamer Spring Hackfest 2016
After missing the last few GStreamer hackfests I finally managed to attend this time. It was held in Thessaloniki, Greece’s second largest city. The city is located by the sea side and the entire hackfest and related activities were either directly by the sea or just a couple blocks away.
Collabora was very well represented, with Nicolas, Mathieu, Lubosz also attending.
Nicolas concentrated his efforts on making kmssink and v4l2dec work together to provide zero-copy decoding and display on a Exynos 4 board without a compositor or other form of display manager. Expect a blog post soon explaining how to make this all fit together.
Lubosz showed off his VR kit. He implemented a viewer for planar point clouds acquired from a Kinect. He’s working on a set of GStreamer plugins to play back spherical videos. He’s also promised to blog about all this soon!
Mathieu started the hackfest by investigating the intricacies of Albanian customs, then arrived on the second day in Thessaloniki and hacked on hotdoc, his new fancy documentation generation tool. He’ll also be posting a blog about it, however in the meantime you can read more about it here.
As for myself, I took the opportunity to fix a couple GStreamer bugs that really annoyed me. First, I looked into bug #766422: why glvideomixer and compositor didn’t work with RTSP sources. Then I tried to add a ->set_caps() virtual function to GstAggregator, but it turns out I first needed to delay all serialized events to the output thread to get predictable outcomes and that was trickier than expected. Finally, I got distracted by a bee and decided to start porting the contents of docs.gstreamer.com to Markdown and updating it to the GStreamer 1.0 API so we can finally retire the old GStreamer.com website.
I’d also like to thank Sebastian and Vivia for organising the hackfest and for making us all feel welcomed!


SUSE Ruling the Stack in Vancouver

Last week during the the OpenStack Summit in Vancouver, Intel organized a Rule the Stack contest. That's the third one, after Atlanta a year ago and Paris six months ago. In case you missed earlier episodes, SUSE won the two previous contests with Dirk being pretty fast in Atlanta and Adam completing the HA challenge so we could keep the crown. So of course, we had to try again!
For this contest, the rules came with a list of penalties and bonuses which made it easier for people to participate. And indeed, there were quite a number of participants with the schedule for booking slots being nearly full. While deploying Kilo was a goal, you could go with older releases getting a 10 minutes penalty per release (so +10 minutes for Juno, +20 minutes for Icehouse, and so on). In a similar way, the organizers wanted to see some upgrade and encouraged that with a bonus that could significantly impact the results (-40 minutes) — nobody tried that, though.
And guess what? SUSE kept the crown again. But we also went ahead with a new challenge: outperforming everyone else not just once, but twice, with two totally different methods.
For the super-fast approach, Dirk built again an appliance that has everything pre-installed and that configures the software on boot. This is actually not too difficult thanks to the amazing Kiwi tool and all the knowledge we have accumulated through the years at SUSE about building appliances, and also the small scripts we use for the CI of our OpenStack packages. Still, it required some work to adapt the setup to the contest and also to make sure that our Kilo packages (that were brand new and without much testing) were fully working. The clock result was 9 minutes and 6 seconds, resulting in a negative time of minus 10 minutes and 54 seconds (yes, the text in the picture is wrong) after the bonuses. Pretty impressive.
But we also wanted to show that our product would fare well, so Adam and I started looking at this. We knew it couldn't be faster than the way Dirk picked, and from the start, we targetted the second position. For this approach, there was not much to do since this was similar to what he did in Paris, and there was work to update our SUSE OpenStack Cloud Admin appliance recently. Our first attempt failed miserably due to a nasty bug (which was actually caused by some unicode character in the ID of the USB stick we were using to install the OS... we fixed that bug later in the night). The second attempt went smoother and was actually much faster than we had anticipated: SUSE OpenStack Cloud deployed everything in 23 minutes and 17 seconds, which resulted in a final time of 10 minutes and 17 seconds after bonuses/penalties. And this was with a 10 minutes penalty due to the use of Juno (as well as a couple of minutes lost debugging some setup issue that was just mispreparation on our side). A key contributor to this result is our use of Crowbar, which we've kept improving over time, and that really makes it easy and fast to deploy OpenStack.
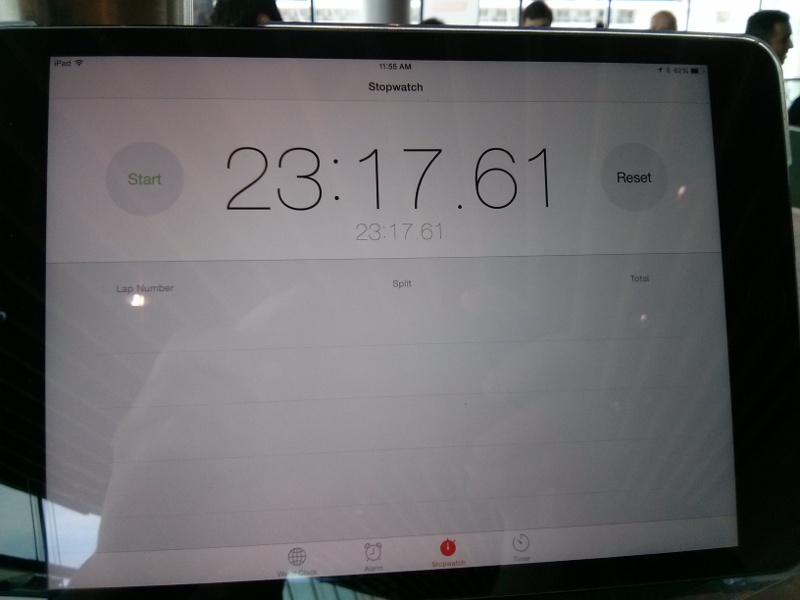
Wall-clock time for SUSE OpenStack Cloud
These two results wouldn't have been possible without the help of Tom and Ralf, but also without the whole SUSE OpenStack Cloud team that works on a daily basis on our product to improve it and to adapt it to the needs of our customers. We really have an awesome team (and btw, we're hiring)!
For reference, three other contestants succeeded in deploying OpenStack, with the fastest of them ending at 58 minutes after bonuses/penalties. And as I mentioned earlier, there were even more contestants (including some who are not vendors of an OpenStack distribution), which is really good to see. I hope we'll see even more in Tokyo!

Results of the Rule the Stack contest
Also thanks to Intel for organizing this; I'm sure every contestant had fun and there was quite a good mood in the area reserved for the contest.
Update: See also the summary of the contest from the organizers.
Deploying Docker for OpenStack with Crowbar
A couple of months ago, I was meeting colleagues of mine working on Docker and discussing about how much effort it would be to add support for it to SUSE OpenStack Cloud. It's been something that had been requested for a long time by quite a number of people and we never really had time to look into it. To find out how difficult it would be, I started looking at it on the evening; the README confirmed it shouldn't be too hard. But of course, we use Crowbar as our deployment framework, and the manual way of setting it up is not really something we'd want to recommend. Now would it be "not too hard" or just "easy"? There was only way to know that... And guess what happened next?
It took a couple of hours (and two patches) to get this working, including the time for packaging the missing dependencies and for testing. That's one of the nice things we benefit from using Crowbar: adding new features like this is relatively straight-forward, and so we can enable people to deploy a full cloud with all of these nice small features, without requiring them to learn about all the technologies and how to deploy them. Of course this was just a first pass (using the Juno code, btw).
Fast-forward a bit, and we decided to integrate this work. Since it was not a simple proof of concept anymore, we went ahead with some more serious testing. This resulted in us backporting patches for the Juno branch, but also making Nova behave a bit better since it wasn't aware of Docker as an hypervisor. This last point is a major problem if people want to use Docker as well as KVM, Xen, VMware or Hyper-V — the multi-hypervisor support is something that really matters to us, and this issue was actually the first one that got reported to us ;-) To validate all our work, we of course asked tempest to help us and the results are pretty good (we still have some failures, but they're related to missing features like volume support).
All in all, the integration went really smoothly :-)
Oh, I forgot to mention: there's also a docker plugin for heat. It's now available with our heat packages now in the Build Service as openstack-heat-plugin-heat_docker (Kilo, Juno); I haven't played with it yet, but this post should be a good start for anyone who's curious about this plugin.
Everyone has been blogging about GUADEC, but I’d like to talk about my other favorite conference of the year, which is GNOME.Asia. This year, it was in Beijing, a mightily interesting place. Giant megapolis, with grandiose architecture, but at the same time, surprisingly easy to navigate with its efficient metro system and affordable taxis. But the air quality is as bad as they say, at least during the incredibly hot summer days where we visited.
The conference itself was great, this year, co-hosted with FUDCon’s asian edition, it was interesting to see a crowd that’s really different from those who attend GUADEC. Many more people involved in evangelising, deploying and using GNOME as opposed to just developing it, so it allows me to get a different perspective.
On a related note, I was happy to see a healthy delegation from Asia at GUADEC this year!
![]()

I've recently looked again at this, but this time with the goal of documenting the build process, and making the build as easy as possible to reproduce. This is once again based off gtk-osx, with an additional moduleset containing the SPICE modules, and a script to download/install most of what is needed. I've also switched to building remote-viewer instead of vinagre
This time, I've documented all of this work, but all you should have to do to build remote-viewer for OSX is to run a script, copy a configuration file to the right place, and then run a usual jhbuild build. Read the documentation for more detailed information about how to do an OSX build.
I've uploaded a binary built using these instructions, but it's lacking some features (USB redirection comes to mind), and it's slow, etc, etc, so .... patches welcome! ;) Feel free to contact me if you are interested in making OSX builds and need help getting started, have build issues, ...
FOSDEM 2013 Crossdesktop devroom Call for talks
Proposals should be sent to the crossdesktop devroom mailing list (you don't have to subscribe).

Going to RMLL (LSM) and Debconf!
Next week, I’ll head to Strasbourg for Rencontres Mondiales du Logiciel Libre 2011. On monday morning, I’ll be giving my Debian Packaging Tutorial for the second time. Let’s hope it goes well and I can recruit some future DDs!
Then, at the end of July, I’ll attend Debconf again. Unfortunately, I won’t be able to participate in Debcamp this year, but I look forward to a full week of talks and exciting discussions. There, I’ll be chairing two sessions about Ruby in Debian and Quality Assurance.
It’s been a long time since I blogged about Libgda (and for the matter since I blogged at all!). Here is a quick outline on what has been going on regarding Libgda for the past few months:
- Libgda’s latest version is now 4.2.4
- many bugs have been corrected and it’s now very stable
- the documentation is now faily exhaustive and includes a lot of examples
- a GTK3 branch is maintained, it contains all the modifications to make Libgda work in the GTK3 environment
- the GdaBrowser and GdaSql tools have had a lot of work and are now both mature and stable
- using the NSIS tool, I’ve made available a new Windows installer for the GdaBrowser and associated tools, available at http://www.gnome.org/~vivien/GdaBrowserSetup.exe. It’s only available in English and French, please test it and report any error.
In the next months, I’ll work on polishing even more the GdaBrowser tool which I use on a daily basis (and of course correct bugs).

Webkit fun, maths and an ebook reader
I have been toying with webkit lately, and even managed to do some pretty things with it. As a consequence, I haven’t worked that much on ekiga, but perhaps some of my experiments will turn into something interesting there. I have an experimental branch with a less than fifty lines patch… I’m still trying to find a way to do more with less code : I want to do as little GObject-inheritance as possible!
That little programming was done while studying class field theory, which is pretty nice on the high-level principles and somewhat awful on the more technical aspects. I also read again some old articles on modular forms, but I can’t say that was “studying” : since it was one of the main objects of my Ph.D, that came back pretty smoothly…
I found a few minutes to enter a brick-and-mortar shop and have a look at the ebook readers on display. There was only *one* of them : the sony PRS-600. I was pretty unimpressed : the display was too dark (because it was a touch screen?), but that wasn’t the worse deal breaker. I inserted an SD card where I had put a sample of the type of documents I read : they showed up as a flat list (pain #1), and not all of them (no djvu) (pain #2) and finally, one of them showed up too small… and ended up fully unreadable when I tried to zoom (pain #3). I guess that settles the question I had on whether my next techno-tool would be a netbook or an ebook reader… That probably means I’ll look more seriously into fixing the last bug I reported on evince (internal bookmarks in documents).
With the beginning of the year comes new releases of Libgda:
- version 4.0.6 which contains corrections for the stable branch
- version 4.1.4, a beta version for the upcoming 4.2 version
The 4.1.4’s API is now considered stable and except for minor corrections should not be modified anymore.
This new version also includes a new database adaptator (provider) to connect to databases through a web server (which of course needs to be configured for that purpose) as illustrated by the followin diagram:

The database being accessed by the web server can be any type supported by the PEAR::MDB2 module.
The GdaBrowser application now supports defining presentation preferences for each table’s column, which are used when data from a table’s column need to be displayed:

The UI extension now supports improved custom layout, described through a simple XML syntax, as shown in the following screenshot of the gdaui-demo-4.0 program:

For more information, please visit the http://www.gnome-db.org web site.
I have been a little stuck for some weeks : a new year started (no, that post hasn’t been stuck since january — scholar year start in september) and I have students to tend to. As I have the habit to say : good students bring work because you have to push them high, and bad students bring work because you have to push them from low! Either way, it has been keeping me pretty busy.
Still, I found the time to read some more maths, but got lost on something quite unrelated to my main objective : I just read about number theory and the ideas behind the proof of Fermat’s Last Theorem (Taylor and Wiles’ theorem now). That was supposed to be my second target! Oh, well, I’ll just try to hit my first target now (Deligne’s proof of the Weil conjectures). And then go back to FLT for a new and deeper reading.
I only played a little with ekiga’s code — mostly removing dead code. Not much : low motivation.
Slides from RMLL (and much more)
So, I’m back from the Rencontres Mondiales du Logiciel Libre, which took place in Nantes this year. It was great to see all those people from the french Free Software community again, and I look forward to seeing them again next year in Bordeaux (too bad the Toulouse bid wasn’t chosen).
The Debian booth, mainly organized by Xavier Oswald and Aurélien Couderc, with help from Raphaël, Roland and others (but not me!), got a lot of visits, and Debian’s popularity is high in the community (probably because RMLL is mostly for über-geeks, and Debian’s market share is still very high in this sub-community).
I spent quite a lot of time with the Ubuntu-FR crew, which I hadn’t met before. They do an awesome work on getting new people to use Linux (providing great docs and support), and do very well (much better than in the past) at giving a good global picture of the Free Software world (Linux != Ubuntu, other projects do exist and play a very large role in Ubuntu’s success, etc). It’s great to see Free Software’s promotion in France being in such good hands. (Full disclosure: I got a free mug (recycled plastic) with my Ubuntu-FR T-shirt, which might affect my judgement).
I gave two talks, on two topics I wanted to talk about for some time. First one was about the interactions between users, distributions and upstream projects, with a focus on Ubuntu’s development model and relationships with Debian and upstream projects. Second one was about voting methods, and Condorcet in particular. If you attended one of those talks, feedback (good or bad) is welcomed (either in comments or by mail). Slides are also available (in french):
- L’écosystème du Libre: interactions entre projets amonts, distributions et utilisateurs – lâ€
 exemple de Debian et Ubuntu
exemple de Debian et Ubuntu - Méthodes de vote: Comment consulter un groupe de personnes sans fausser le résultat ?
On a more general note, I still don’t understand why the “Mondiales” in RMLL’s title isn’t being dropped or replaced by “Francophones“. Seeing the organization congratulate themselves because 30% of the talks were in english was quite funny, since in most cases, the english part of the talk was “Is there someone not understanding french? no? OK, let’s go on in french.“, and all the announcements were made in french only. Seriously, RMLL is a great (probably the best) french-speaking community event. But it’s not FOSDEM: different goals, different people. Instead of trying (and failing) to make it an international event, it would be much better to focus on making it a better french-speaking event, for example by getting more french-speaking developers to come and talk (you see at least 5 times more french-speaking developers in FOSDEM than in RMLL).
I’m now back in Lyon for two days, before leaving to Montreal Linux Symposium, then coming back to Lyon for three days, then Debconf from 23rd to 31st, and then moving to Nancy, where I will start as an assistant professor in september (a permanent (tenured) position).

On September I finish my studies of computer science, so I start to search a job. I really enjoyed my current job at Collabora maintaining Empathy, I learned lots of things about the Free Software world and I would like to keep working on free software related projects if possible. My CV is available online here.
Do you guys know any company around the free software and GNOME looking for new employees? You can contact me by email to xclaesse@gmail.com

Enterprise Social Search slideshow
Enterprise Social Search is a way to search, manage, and share information within a company. Who can help you find relevant information and nothing but relevant information? Your colleagues, of course
Today we are launching at Whatever (the company I work for) a marketing campaign for our upcoming product: Knowledge Plaza. Exciting times ahead!
I’ve been working wit git lately but I have also missed the darcs user interface. I honestly think the darcs user interface is the best I’ve ever seen, it’s such a joy to record/push/pull (when darcs doesn’t eat your cpu) 
I looked at git add --interactive because it had hunk-based commit, a pre-requisite for darcs record-style commit, but it has a terrible user interface, so i just copied the concept: running a git diff, filtering hunks, and then outputing the filtered diff through git apply --cached.
It supports binary diffs, file additions and removal. It also asks for new files to be added even if this is not exactly how darcs behave but I always forget to add new files, so I added it. It will probably break on some extreme corner cases I haven’t been confronted to, but I gladly accept any patches
Here’s a sample session of git-darcs-record script:
$ git-darcs-record
Add file: newfile.txt
Shall I add this file? (1/1) [Ynda] : y
Binary file changed: document.pdf
Shall I record this change? (1/7) [Ynda] : y
foobar.txt
@@ -1,3 +1,5 @@
line1
line2
+line3
line4
+line5
Shall I record this change? (2/7) [Ynda] : y
git-darcs-record
@@ -1,17 +1,5 @@
#!/usr/bin/env python
-# git-darcs-record, emulate "darcs record" interface on top of a git repository
-#
-# Usage:
-# git-darcs-record first asks for any new file (previously
-# untracked) to be added to the index.
-# git-darcs-record then asks for each hunk to be recorded in
-# the next commit. File deletion and binary blobs are supported
-# git-darcs-record finally asks for a small commit message and
-# executes the 'git commit' command with the newly created
-# changeset in the index
-
-
# Copyright (C) 2007 Raphaël Slinckx
#
# This program is free software; you can redistribute it and/or
Shall I record this change? (3/7) [Ynda] : y
git-darcs-record
@@ -28,6 +16,19 @@
# along with this program; if not, write to the Free Software
# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
+# git-darcs-record, emulate "darcs record" interface on top of a git repository
+#
+# Usage:
+# git-darcs-record first asks for any new file (previously
+# untracked) to be added to the index.
+# git-darcs-record then asks for each hunk to be recorded in
+# the next commit. File deletion and binary blobs are supported
+# git-darcs-record finally asks for a small commit message and
+# executes the 'git commit' command with the newly created
+# changeset in the index
+
+
+
import re, pprint, sys, os
BINARY = re.compile("GIT binary patch")
Shall I record this change? (4/7) [Ynda] : n
git-darcs-record
@@ -151,16 +152,6 @@ def read_answer(question, allowed_responses=["Y", "n", "d", "a"]):
return resp
-def setup_git_dir():
- global GIT_DIR
- GIT_DIR = os.getcwd()
- while not os.path.exists(os.path.join(GIT_DIR, ".git")):
- GIT_DIR = os.path.dirname(GIT_DIR)
- if GIT_DIR == "/":
- return False
- os.chdir(GIT_DIR)
- return True
-
def git_get_untracked_files():
Shall I record this change? (5/7) [Ynda] : y
# On branch master
# Changes to be committed:
# (use "git reset HEAD file..." to unstage)
#
# modified: document.pdf
# modified: foobar.txt
# modified: git-darcs-record
# new file: newfile.txt
#
# Changed but not updated:
# (use "git add file file..." to update what will be committed)
#
# modified: git-darcs-record
#
What is the patch name? Some cute patch name
Created commit a08f34e: Some cute patch name
4 files changed, 3 insertions(+), 29 deletions(-)
create mode 100644 newfile.txt
Get the script here: git-darcs-record script and put in somewhere in your $PATH. Any comments or improvements is welcome !
Un nouveau laptop, sans windows !
Voilà, j’y pensais depuis longtemps et c’est maintenant chose faite, je me suis acheté un tout nouveau ordinateur portable.
Je l’ai acheté sur le site français LDLC.com et me suis renseigné pour savoir si il était possible d’acheter les ordinateurs de leur catalogue sans logiciels (principalement sans windows). Je leur ai donc envoyé un email, et à ma grande surprise ils m’on répondu que c’était tout a fait possible, qu’il suffi de passer commande et d’envoyer ensuite un email pour demander de supprimer les logiciels de la commande. J’ai donc commandé mon laptop et ils m’ont remboursé de 20€ pour les logiciels, ce n’est pas énorme sur le prix d’un portable, mais symboliquement c’est déjà ça.
Toutes fois je me pose des questions, pourquoi cette offre n’est pas inscrite sur le site de LDLC ? En regardant sous mon tout nouveau portable je remarque une chose étrange, les restes d’un autocollant qu’on a enlevé, exactement à l’endroit où habituellement est collé la clef d’activation de winXP. Le remboursement de 20€ tout rond par LDLC me semble également étrange vue que LDLC n’est qu’un intermédiaire, pas un constructeur, et donc eux achètent les ordinateurs avec windows déjà installé. Bref tout ceci me pousse à croire que c’est LDLC qui perd les 20€ et je me demande dans quel but ?!? Pour faire plaisir aux clients libre-istes ? Pour éviter les procès pour vente liée ? Pour à leur tours se faire rembourser les licences que les clients n’ont pas voulu auprès du constructeur/Microsoft et éventuellement gagner plus que 20€ si les licences OEM valent plus que ça ? Bref ceci restera sans doutes toujours un mistère.
J’ai donc installé Ubuntu qui tourne plutôt bien. J’ai été même très impressionné par le network-manager qui me connecte automatiquement sur les réseaux wifi ou filaire selon la disponibilité et qui configure même un réseau zeroconf si il ne trouve pas de server dhcp, c’est très pratique pour transférer des données entre 2 ordinateurs, il suffi de brancher un cable ethernet (ça marche aussi par wifi mais j’ai pas encore testé) entre les 2 et hop tout le réseau est configuré automatiquement sans rien toucher, vraiment magique ! Windows peut aller se cacher, ubuntu est largement plus facile d’utilisation !
I hate having to write about bugs in the documentation. It feels like waving a big flag that says ‘Ok, we suck a bit’.
Today, it’s the way fonts are installed, or rather, they aren’t. The Fonts folder doesn’t show the new font, and the applications that are already running don’t see them.
So I’ve fixed the bug that was filed against the documentation. Now it’s up to someone else to fix the bugs in Gnome.
Choice and flexibility: bad for docs
Eye of Gnome comes with some nifty features like support for EXIF data in jpegs. But this depends on a library that isn’t a part of Gnome.
So what do I write in the user manual for EOG?
‘You can see EXIF data for an image, but you need to check the innards of your system first.’
‘You can maybe see EXIF data. I don’t know. Ask your distro.’
‘If you can’t see EXIF data, install the libexif library. I’m sorry, I can’t tell you how you can do that as I don’t know what sort of system you’re running Gnome on.’
The way GNU/Linux systems are put together is perhaps great for people who want unlimited ability to customize and choose. But it makes it very hard to write good documentation. In this sort of scenario, I would say it makes it impossible, and we’re left with a user manual that looks bad.
I’ve added this to the list of use cases for Project Mallard, but I don’t think it’ll be an easy one to solve.